Retrofitting the Web
Dorian Taylor
My professional focus has been, as long as I can remember, about designing for comprehension. That is, understanding what’s going on in one’s surroundings, how things in the world work, and effective ways of thinking and talking about it. I’ve long been dissatisfied with communication media in general, and the World-Wide Web in particular. I believe the information it carries is too sparse—too much content for not enough information—and that its capabilities are underutilized. In our present milieu of global warming, authoritarian backsliding, conspiracy theories, AI hype, and scammers around every corner, situation awareness1 has never been more important. As a civilization, however, it seems to be a skill we lack. What follows is my framing of the issue and what I’m doing about it.
Be sure to check out the companion video to this article, that goes into more detail about the concrete problems I’m working to solve.2
Alan Kay,3 prominent computer scientist, and equally eminent pedagogical theorist, in a 1995 presentation,4 posited three modalities of thinking, in increasing levels of difficulty:
- stories
- arguments (the logical reasoning kind)
- system5 dynamics (which I will refer to interchangeably as models and data).
The thinking—Kay’s, that is—goes like this: everybody understands stories, because we’re hardwired for stories. A small fraction of the population—he figures somewhere between five and eight percent—are fluent in logical argumentation, and an immeasurably narrow subgroup pilot their daily lives in terms of models and data. If you stop reading the talk transcript right there, you might infer that Kay is suggesting that there is some kind of innate intellectual stratification in place: an elite few who genuinely understand what’s really going on, a retainer caste who advances their framing of how the world works, and everybody else is in the mud wrangling gossip and fairy tales. Rather, Kay supposes—as do I—that it is an issue of training. The refrain from educators is that learning model-literacy is hard, but he remarks that people learn hard things all the time. Children in particular will resolutely endure repeated failure in the process of acquiring a skill if they believe eventual success to be culturally significant. I submit this generalizes. People are actually pretty rational about the prospect of learning something new: they’re willing to invest if they perceive both that they can afford the downtime, and that the outcome is worth the effort.
The cultural value of gaining comprehension is situated in time and space, relative to the person, and highly dynamic. We can assume the effort is always a cost, but the resulting knowledge and/or mastery is not always an asset. “Am I the kind of person who . . .” knows how to perform partial differential equations or how to thoroughly clean a toilet? A business executive might say no, because he perceives these skills, useful as they are, to be beneath him. Conversely, “will my peers hold me in higher esteem . . .” if I develop an encyclopaedic knowledge of wine? Probably not if I’m a dock worker. I would likely alienate them—give them the impression that I believed myself “better” somehow. At best they’d make fun of me; at worst they’d ostracize or even attack me for it. People are sensitive not just to cost of learning something new, but to the potential social downside of possessing the resulting knowledge.
The process of learning itself is riddled with opportunities to lose face. Learning is always unproductive in the short term, so you may be accused of wasting time, especially if you don’t have a likely shot at being the best—or at least a ranking contender—at whatever it is. Likewise, if it’s important to you to always appear competent and in control of the situation, you could easily find yourself publicly humiliated. Even something as innocuous as learning a new word presents the social pitfall of using or even just pronouncing it wrong. In the process of gaining comprehension, the ability to both conceal the effort and fail discreetly are dimensions worth considering.
This gives us two degrees of freedom to consider when gaining comprehension: the outlay of the effort itself—including its attendant risks—and how conspicuously valuable is the net benefit. Which brings me back to stories:
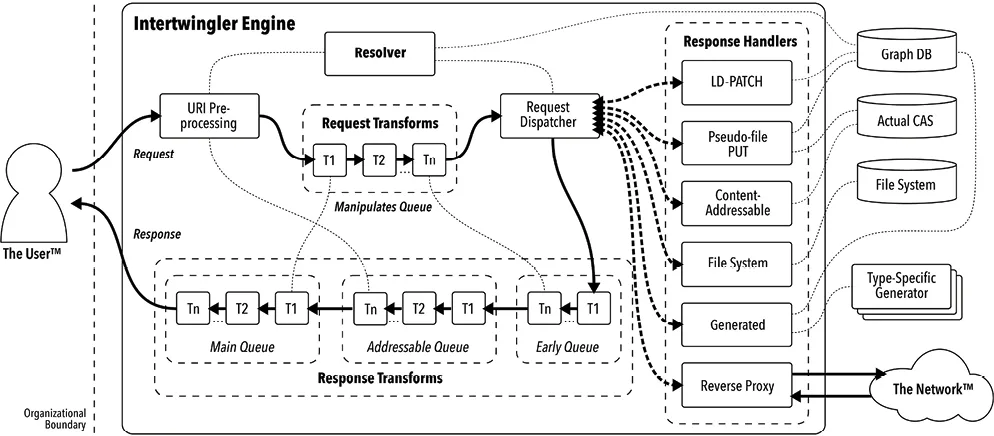
This diagram depicts the flow of HTTP requests from the user into Intertwingler and responses back out. Other generic components included for context. (Details at intertwingler.net)
- Stories have characters
(heroes, villains, and other), - the characters do things
(including nothing), - their actions (or lack of action) have consequences,
- the consequences are either good or bad (or some mixture of both),
- the character(s) either deserve the outcome, or they don’t.
While I admit this framing is reductive, the observation here is that the median story presents almost nothing to learn, besides who the players are and which ones of them to root for. With some exceptions—like science fiction and other speculative work where imagining other realities is kind of the point—stories operate within the confines of system dynamics that everybody is inherently familiar with. Stories are a point sample—an existence proof—either affirming that our incumbent mental model of the world is correct, or otherwise that its dynamics yield unexpected, yet plausible results. In other words, stories inform our own conduct within a model, worldview, system, or paradigm; very rarely do they challenge it, especially head on. In any case, the capacity for stories to communicate new models is sharply limited, because that’s the realm of argumentation—or heaven forbid, exposition—which in the middle of a story is dull as all hell.
We can think of logical argumentation, then, as rigorously stepping through a path within a given model. We see this pattern in legal arguments and mathematical proofs: if the world is like that, then we can conclude this. We also begin to see evidence of paradigmatic frontal assault: works of science and philosophy routinely suggest that maybe the world isn’t like that, but rather like this. The problem with following a line of argumentation is that it’s immensely taxing on your attention, you have to understand all the parts in order to understand the whole, and the benefit doesn’t come until you’ve assimilated the entire thing. If you don’t understand all the parts and pieces of the argument, then you have to learn them on the fly. This smacks of effort, and is even farther removed from the straightforward—not to mention manifestly applicable—insights of a story.
So while most of us may think in terms of stories, I’m going to suggest that system dynamics are actually what give us agency, whether we’re aware of them or not. System dynamics are all about inferring the unseen (model) from the seen (data). Models are about predicting the future from the past and present—at least within some tolerance that the model remains useful. If I push on this part, then that part will poke out. If I see this, then it probably means that. The model doesn’t have to be precise, but it does have to be accurate.6 You don’t need a PhD in quantum electrodynamics to understand that a lamp has to be plugged in first before you can turn it on. You don’t have to know the details of how a car works in order to drive it from one place to another without getting killed. You don’t have to appreciate the intricacies of plate tectonics or global geopolitics to understand that you should probably cancel your vacation plans to a country that has just undergone an earthquake—or a coup.
So when I say model, I mean a kind of formal structure of entities connected by relationships, that represents some part of reality (or maybe it’s fiction! or maybe something that doesn’t exist yet) and is useful for reasoning about it. The entities and relationships can be concrete and qualitative, like a family tree, or they can be quantitative, and help us reason over things that are hard to perceive, like Ohm’s law.7 Or they can be purely conceptual, or they can be a mix. Models can be simple, or they can be complex. A model is not necessarily an artifact—it can live entirely in your head—though it firms up a great deal if you try to express it as one. All models are systems, with dynamics that approximate the systems they represent, and the point of a model8 is to better understand—through data—what its assigned bit of reality is capable of. Models help us understand in advance what reality can do, so you know what you should do in response if it ever happens for real.
Everybody (Cargo) Cults, Sometimes
A story is like a replay of an instance of a causal model. Protagonist did this, and the outcome was { good, bad }, so therefore I will { copy, avoid } what they did. There’s the cliché that correlation is not causation, but I submit that the whole point of a story is to imply causation, if not outright assert it. What kind of story would it be if one thing happened, and then another thing happened, and they had nothing to do with each other, the end? Not a very interesting one!
At any rate, copying what you hear in a story to get a similar outcome is not a half-bad heuristic. If a person says they went to a particular restaurant and had a great meal, chances are so will you. If they say stay away from this part of town because they know a guy who got mugged, and you don’t go, you won’t get mugged—at least in that neighbourhood—but there’s an opportunity cost. However, because you didn’t go, you can’t quantify that opportunity cost, so the number may as well be zero. Using stories to inform one’s own conduct is reasonably okay at yielding reasonably okay results, enough of the time. Where it falls apart is in the fact that stories only hint at system dynamics, if they even invoke them at all. The fact that your cousin got rich because he bought a quantity of some random cryptocurrency at just the right time emphatically does not mean that you will too if you go buy some of it right now.
The extreme example here is the cargo cult,9 a real social phenomenon that occurred in the South Pacific, stemming from the activities of the Second World War. Inhabitants of certain Pacific islands would watch the Americans outfit their bases by airdrop. Sometimes the planes would drop the crates onto the wrong beach, and the people would find them and open them, and discover all sorts of great stuff inside. So they reasoned that all you had to do to get more of that great stuff was copy what the Americans were doing—so, control towers made of bamboo, radar dishes made of palm fronds, that kind of thing. And the thing was, misdirected airdrops happened often enough to convince these people that what they were doing was working. “Cargo culting” has since become a verb, especially in matters to do with computers, for copying behaviour without understanding the underlying mechanism.
The term has more recently fallen into disfavour due to racist connotations, which I agree does hold if you’re trying to say something about the intelligence and/or worldliness of certain Pacific Islanders. But getting caught up in that discourse short-circuits asking the question: on what basis should we expect them to have known? Gaining comprehension is contingent on time, effort, and importantly for the original cargo cultists, access to specific information. (Even upon receipt of said information, there would undoubtedly also have been political incentives to keep the cults going anyway, evidenced by the fact that a few of them still exist.) All of us, when short on one or more of these ingredients while trying to get something done—which we often are—will try to copy a solution first before attempting to understand it. Everybody cargo cults; the original cargo cultists were just a conspicuous early example.
The reason why the restaurant recommendation works and the investment advice does not is because the people who work at the restaurant do everything in their power to provide a consistently high quality experience from one day (week, month, year…) to the next, while chaotic, leaderless systems like markets do nothing of the sort. Indeed, the people who earn their living in the markets, which includes those that helm corporations, are all about models, almost—or less than almost—to a fault. When it actually matters that your decisions and actions reliably perform, stories just won’t cut it: you need models to be effective.
Under the model-driven regime, stories take on a different role: they indicate when your model has stopped working, if you’re wise enough to pay attention to them. One reason for the 2008 financial crisis is that Wall Street types spent too much time looking at models and not enough time listening to stories.
System Dynamics Are Hard, Let’s Go Shopping
The trivial mental model that comes along for the ride with a story is on the order of “if I do what the protagonist did, then I will get the outcome the protagonist got.” This is, once again, highly contingent on the exact conditions at the time, a significant subset of which would have to be the same for you if you were to expect the same outcome. The heuristic works for stable situations, not so much for dynamic ones. The causal pattern in stories can likewise conflict with each other: two stories could have diametrically opposite moral messages despite nearly-identical fact patterns, and you just pick the one that suits you in the moment. The two micro-models never collide inside a person’s head, and they never realize that both stories can’t be true at the same time.
I would be remiss if I didn’t mention the 2009 paper by Mercier and Sperber10 that hypothesizes that reason itself evolved for purely rhetorical purposes, and it’s only a side effect that things like math and logic and engineering and science and general problem-solving developed out of it. The authors note, as have those writing as far back as Aristotle or Cicero, that reason is actually the weakest form of rhetoric, because it requires the audience to follow you all the way from beginning to end, paying intense attention the entire time. As such it’s only useful for convincing those who are already somewhat sympathetic—or at worst, neutral—and are angling for a robust justification to take your side. It takes no effort to just ignore your arguments, which is why people who have already made up their mind don’t “listen to reason.”
Consider the situation with COVID masks: early on in the pandemic, prior to vaccines, prior to the availability of rapid tests, when the extent of the danger was still poorly understood, we wore masks as a hedge in case we were infected, so we would be less likely to infect other people. Under this regime, any mask was better than nothing. Three years later, now that the virus has become an inexorable fact of life, everybody who was ever to be vaccinated has been, and all the legal restrictions have been lifted, the regime is now different: if you’re still wearing a mask, it’s to protect yourself. In this situation, the kind of mask becomes much more important. Wearing it correctly becomes much more important. I nevertheless still see people walking around outside (where masks have always mattered the least) wearing cheap surgical masks with their noses hanging out. What that suggests to me is that they have a broken (if any) mental model of how viruses work, probably never understood what the masks were for in the first place, and now just wear one quasi-superstitiously as some kind of ward or talisman. Classic story thinking: “wear the mask, or else.”
COVID-19 is a perfect example of a situation where it would have been highly advantageous to be able to communicate “just enough model” to people en masse. Again, the model doesn’t have to be precise, it just has to be accurate. You don’t need to be trained in virology, epidemiology, fluid dynamics, probability theory, or materials engineering to have a good-enough mental model of what kind of mask will be effective and when, but one that works for the whole pandemic and even non-pandemic-related things.
If for some reason you want higher-resolution details, you can fill those in later.
The cool thing about models is they nucleate: they connect to other models inside your mind to make bigger models to make sense of more things about the world. This is because everything in the world has as least a little bit to do with everything else, so you may find that the edges of one model will meet up with another. You might also find that the dynamics of one model are very similar to the dynamics of another, and construct a new, more abstract mental model that handles them both. These “compression events” are highly sought after in physics, for example—indeed, that is roughly what theoretical physicists do all day.
Once you’re model-literate, you look for ways to fill out and extend it. There is an almost gravitational pull to do this. In this way models are not exactly self-assembling, since we’re the ones assembling them, but there is a strong drive to do so—which is good, because models go stale and need to be kept up to date so they match reality.
When I said models can be used as a synonym for system dynamics, I actually mean models and data. Data is what plugs into models, and that’s what gives models dynamics. Moreover, you don’t actually need a lot of data for a model to do interesting things. Setting up the model can be expensive, but it’s something you only do once. Animating it with data, on the other hand, is cheap.
I feel obligated to remark once again that when I say “models” I mean conceptual, possibly mathematical or computational models in general (at least, one would hope they could be rendered computable), and not things like large language models, which, being statistical in nature, are constructed from veritable oceans of data. But even those, once trained, don’t need a lot of input to give you something useful.
The stepwise nature of baseball, for instance, gives it an unusually large repertoire of things that you can count. Avid fans—which, I should add, is a completely respectable thing to be, whether in the warehouse or the boardroom—can look at a handful of numbers and recreate an entire game in their heads. I don’t partake myself, but I understand fantasy leagues are this dynamic happening at scale.
See? People can handle models just fine, when the incentives are right.
Still, there remains the problem of how do you transmit a model. Stories don’t get you to models, because models are much denser than stories. Consider a popular book or movie franchise—Star Wars, Harry Potter, Lord of the Rings, Marvel—the “universe” is the model here, and the whole point of having one is you can generate infinitely many stories with it. So how many stories would you need to tell to ensure you covered the entire universe? Arguments and exposition are of course much denser than stories (although not as dense as models, unless the exposition is the model), because they do away with things like characters, setting, and plot, which is precisely the thing 95% of the planet has no stamina for.
This is a serious problem, because there are people in charge who are incapable of understanding the dynamics of the very systems they’re in charge of (tech policy, climate, you name it), because they are incapable of understanding system dynamics in general. Even if you said something like leadership positions are skewed toward model literacy (plausible), it’s still a statistical likelihood that the people holding those positions aren’t. The people who vote those people into power (it’s not just politicians though, but judges, CEOs . . .) are going to be as bad, or even worse off.
This is against a backdrop of a veritable bullshit renaissance, where the stories are currency. It reminds me of something a designer friend of mine said to me at least 20 years ago: “Do you remember in the 80s when you were on the playground in elementary school, and there would inevitably be some kid who’d make some outlandish claim like the guys in the Teenage Mutant Ninja Turtles costumes were really the New Kids on the Block? And you just had to kinda believe him? That kid would never be able to get away with that now cause you could just look it up.” Two decades later, I’m no longer so sure. It’s even easier to look things up now. People don’t have trouble looking things up if they want the answer; what’s become clear to me over the last five or six years is that they don’t.
It is my concern that stories, the one modality of communication everybody understands, are too sparse to carry the quantity of information needed to make sense of the world. Sequential argumentation and exposition—the one you’re reading, for example—likewise. We need to get more people model-literate, which means an order-of-magnitude (or two) increase in the efficiency of uptake. We need to figure out a way to bulk-load models into people’s heads, simultaneously bringing the cost down and the salience up so it becomes something people perceive to be worth doing. It also wouldn’t hurt to make the process of model uptake fun, or at least as interesting as one can get away with. Make it something you can leave and come back to. Create the space to learn (and fail!) discreetly, with no stigma. Make it easy to share and get other people involved.
It may turn out, after all this, that some people will be constitutionally incapable of understanding system dynamics no matter how cheap or interesting you make it. If that’s the case, models will still be valuable to the people who are model-literate, to help construct denser stories, which will be better than nothing.
This is already kind of happening. Even though the format of a book or movie hasn’t changed significantly in the last several decades (though TV certainly has), the inputs have become much more sophisticated. I don’t just mean special effects, the writing is much more heavily instrumented.
Okay, so how do you do that?
Well I don’t know if you’ve noticed but there’s these things called computers, and enacting models is literally what computers do all day. Every program is a model of sorts, and the whole point of computers is to run programs and see what they do.
What makes computers a truly revolutionary technology is not their speed per se, or the fact that they are digital, or even electronic. It’s the fact, as I argued in a 2017 talk,11 that they can address a very large number of very small pieces of information, and that the cost of visiting any one address is immeasurably close to visiting any other, which is to say almost nothing. This capability, called random access, is what gives computers their power, because it enables them to construct large, complex systems out of many simple parts, and then run the whole thing in real time. Their capacity, which has grown a million times since computers hit the market—to say nothing of when they started out—is so large that you never have to throw anything out. The economics are such that you can now buy a serviceable computer12 for less than it costs to go to dinner (by yourself).
The irony, with notable exceptions like video games, is that we’re using computers and all their power mostly to simulate the media that came before them: paper, film, telephones, radio, television. These things are purpose-built for models, so we made models (programs) for making stories. Even video games—the notable exception—are almost all stories, though most of the work of a video game is creating an entire universe, just so you can have a story in it.
It’s this capacity for entire universes that really sets computers apart: make a model and then just plunk a person right down in the middle of it. The word for this, according to media theorist Lev Manovich,13 is paradigm, meaning pretty much how you may already be familiar with the term: worldview, model, universe of possibilities. Its complement—and I promise you, this is the only weird new word, is syntagm14—one specific path through the paradigm.
Manovich’s theory is that in media like books and movies, the syntagm—the story—is in the foreground, while the paradigm—the universe—is deep underneath, barely visible. Computers invert this order by foregrounding the paradigm, and making syntagm something that is generated out of it. We can see the effect of this too, as I alluded above, with the thirty-seventh Star Wars spinoff or Marvel movie. Manovich argues that the native form of the computer is the database—that is to say, in a very generic sense, a large agglomerate of tiny pieces of information, interconnected by formal relationships. The way you navigate a database—this isn’t Manovich now, but a guy named Paul Dourish15—is hypertext.
Hypertext, or hypermedia to generalize, is when you take ordinary text (or other conventional media) and add a kind of fractal dimension to it. Rather than start at the beginning of a work and read all the way to the end, you can tunnel through it, rearrange it, skip over parts, drill into details. This characteristic isn’t strictly the province of computers (as masterfully argued by Espen Aarseth in his dissertation16), but computers are especially good at it.
Hypermedia has a rich prehistory—Otlet’s Mundaneum,17 Bush’s Memex,18 Nelson’s Xanadu,19 Engelbart’s NLS,20 and so on—even (as Aarseth argues) experimental novels like Nabokov’s Pale Fire21 and ancient texts like the I Ching22—and of course, Choose Your Own Adventure books.23 In the nascent PC era of the 1980s, people were creating text adventures like Zork,24 interactive works in HyperCard,25 and writing eerie, spatialized novellas in StorySpace.26 And then, in 1991, the World-Wide Web appeared, and we kind of forgot about all of that.
The Web has a lot of extremely desirable characteristics—instantaneous global publication, unlimited scale, unprecedented ease and low cost of deployment—but as hypermedia, it actually kind of sucks. The median website, if you clip off the fixed navigation on every page, may as well be a stack of paper, due to how few links remain. Links, as Ted Nelson27 often complains (he coined the term “hypertext” in 1960, by the way), that only go in one direction, so you can see the links going out, but not the links coming in. There’s no convention for the type of link (my observation), so you can’t tell in advance if a link is a bibliographic citation, a definition, or something else. The Web’s applicability as a delivery mechanism for software, which has turned a thing you buy in a store and pay once for into a permanent economic umbilical, is still very rigid in its structure and variety of connections. Even the fact that the basic unit of the Web is the page biases it toward big, chunky, analog-style documents—that is to say, stories—rather than the sleek, pulverized information of models.
The reason the Web is such a poor specimen of hypermedia, I have diagnosed, is mainly inertia. The Web took off like a rocket in the mid-90s, and the world very quickly developed a consensus about what a website is, as a cultural concept. Its inventor, (Sir) Tim Berners-Lee,28 is aware of this,29 which we know, because almost immediately after he got the Web out the door, he set about retrofitting it—something he called the Semantic Web. Still, in my mind, the Web’s central weakness is also its greatest strength: what Berners-Lee himself credits as his most important invention, the humble URL.
To put it briefly—which I’m sure will be welcome at this point—the benefit of URLs is that they extend the idea of random-access addressing to a global scope: as Uniform Resource Locators, they locate (information) resources in a fashion that is uniform. This is a framework that enables any page on any website to link to any other page on any other website, and things that aren’t websites (e-mail, the phone system, Zoom . . .), and since URLs are just little pieces of text, they can go on a business card, a billboard, or virtually anywhere else. Truly a magnificent technology.
The problem with URLs is twofold: since they’re ultimately descended from file names—indeed, as was the original design, they often reference files directly—deciding what to call them is a separate chore from authoring whatever it is they reference, just as you can’t save a file without deciding what to name it. Because it’s very cheap to rename files—and thus their URLs—and very expensive, if not impossible, to update all the places a given URL is referenced, they tend to be extremely brittle. They’re also awkward and cumbersome to the authoring process. If you want to link to another document, you have to go fish out its URL. Even to date, there is almost no tooling support for this, though we see a glimmer of it in things like Wikipedia (which cheats, in my opinion) and Google Docs (which leverages a multi-billion-dollar infrastructure). But this inherent brittleness creates a downward pressure on the density of linking on the Web: why bother linking to something at all if it’s just going to break in a month?
It’s the URLs, Stupid
Recall my original goal is to make it sharply easier for ordinary people to comprehend system dynamics, by promoting a literacy of models, in turn by making it sharply easier to create models and publish them. The Web already has the basic ingredients for this endeavour, but its own dynamics—the ones it comes with off the shelf—are all out of whack. So my proximate project, then, is to retrofit the Web with a sort of adapter, which, first and foremost, repairs the brittleness of URLs. This paves the way for something I’m calling dense hypermedia to contrast it with the sparsity of information found in conventional websites. By fixing URLs—specifically, by enabling you to defer, perhaps indefinitely, the task of deciding what to call them, and then remembering what the old names were when you do—they become a lot more reliable, meaning it’s possible to dramatically shrink the basic unit while simultaneously cranking up both the number and variety of connections between them.
It literally took me years to understand how important this was, and most of the way through the Summer of Protocols program30 to properly articulate it. The solution is almost embarrassingly straightforward, and doesn’t take a lot of code to express it. It isn’t even especially original—other people have made similar mechanisms—but I’m not aware of any that have taken the principle as far as I have.
The embodiment of this project is a thing I’m calling Intertwingler.31 The most appropriate designation for it is engine, much like the ubiquitous WordPress32 is an engine: you use it to make websites. Unlike WordPress, however, I have no desire for Intertwingler to become a platform. Rather, I view it as a set of demonstrations for what it takes to tackle the URL brittleness problem, and subsequently, the kinds of things one can achieve once the problem is solved. In other words, a protocol. My goal with Intertwingler is to knock the Web, as an archetypal medium, off its orbit, so it becomes the dense hypermedia system the theorists have for decades been clamouring for.
The name itself—with some credit to Venkatesh Rao33 for suggesting something similar—is a nod to Ted Nelson, who, again, made hypertext a thing. To be intertwingled34 is to be inextricably, densely, deeply interlinked, where nothing is truly separate from anything else.
This project comes out of a sense of frustration, as well as a sense of urgency: the world is full of challenges and we need all the help we can get. We need to increase our capacity for understanding the world, and all its system dynamics, by becoming model-literate. And we do that, as a practical matter, by retrofitting the Web into dense hypermedia. This has been my story about the origin of Intertwingler. With any luck, my next major “writing” will be a model. Δ
Dorian Taylor is a self-taught practitioner who grew up in Canada in the dot-com 1.0 era. Just the right age at just the right time, he went from pushing pixels, to running servers, to programming infrastructure, to UX design, experiencing what it’s like to build the Web from every angle while it was still possible to get one’s arms around the entire thing. He now helps clients with strategic planning, developing situation awareness, and the occasional technical heavy lift. doriantaylor.com
-
4. worrydream.com/refs/Kay_1995_-_Powerful_Ideas_Need_Love_Too.html
-
5. Kay actually said systems dynamics, but I’m making the judgment call that it’s okay to use the singular form rather than the plural.
-
10. www.dan.sperber.fr/wp-content/uploads/2009/10/MercierSperberWhydohumansreason.pdf
-
13. mitpress.mit.edu/9780262632553/the-language-of-new-media/
-
14. Pronounced sin-tam. I know. It was a new one for me, too.
-
18. www.theatlantic.com/magazine/archive/1945/07/as-we-may-think/303881/
© 2023 Ethereum Foundation. All contributions are the property of their respective authors and are used by Ethereum Foundation under license. All contributions are licensed by their respective authors under CC BY-NC 4.0. After 2026-12-13, all contributions will be licensed by their respective authors under CC BY 4.0. Learn more at: summerofprotocols.com/ccplus-license-2023
Summer of Protocols :: summerofprotocols.com
ISBN-13: 978-1-962872-19-5 print
ISBN-13: 978-1-962872-45-4 epub
Printed in the United States of America
Printing history: July 2024
Inquiries :: hello@summerofprotocols.com
Cover illustration by Midjourney :: prompt engineering by Josh Davis
«sphere made of infinite links, internet, exploded technical diagram»
